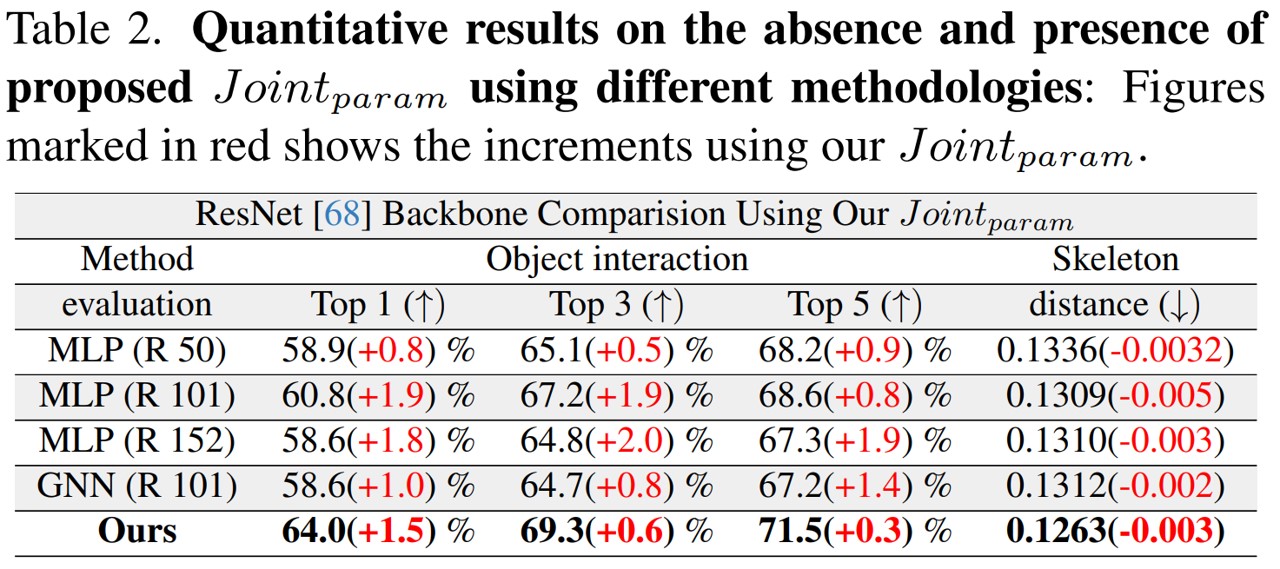
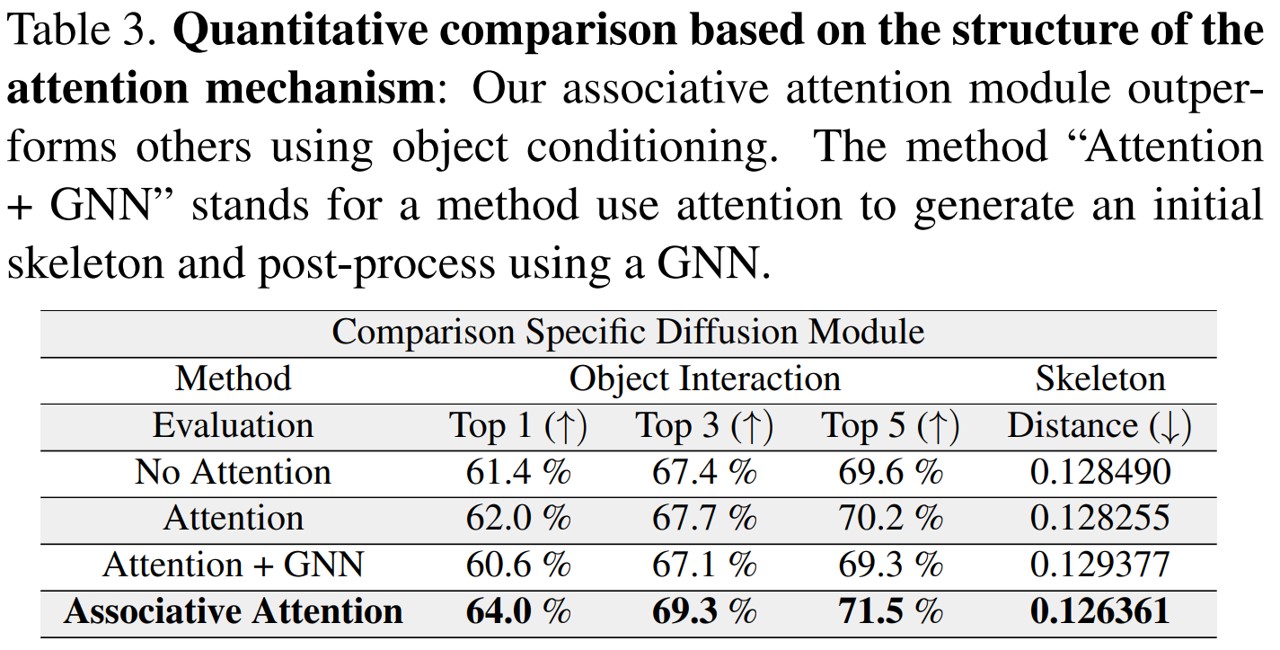
Additional Visualization Results

Comparison between attention mechanism and associative attention mechanism:
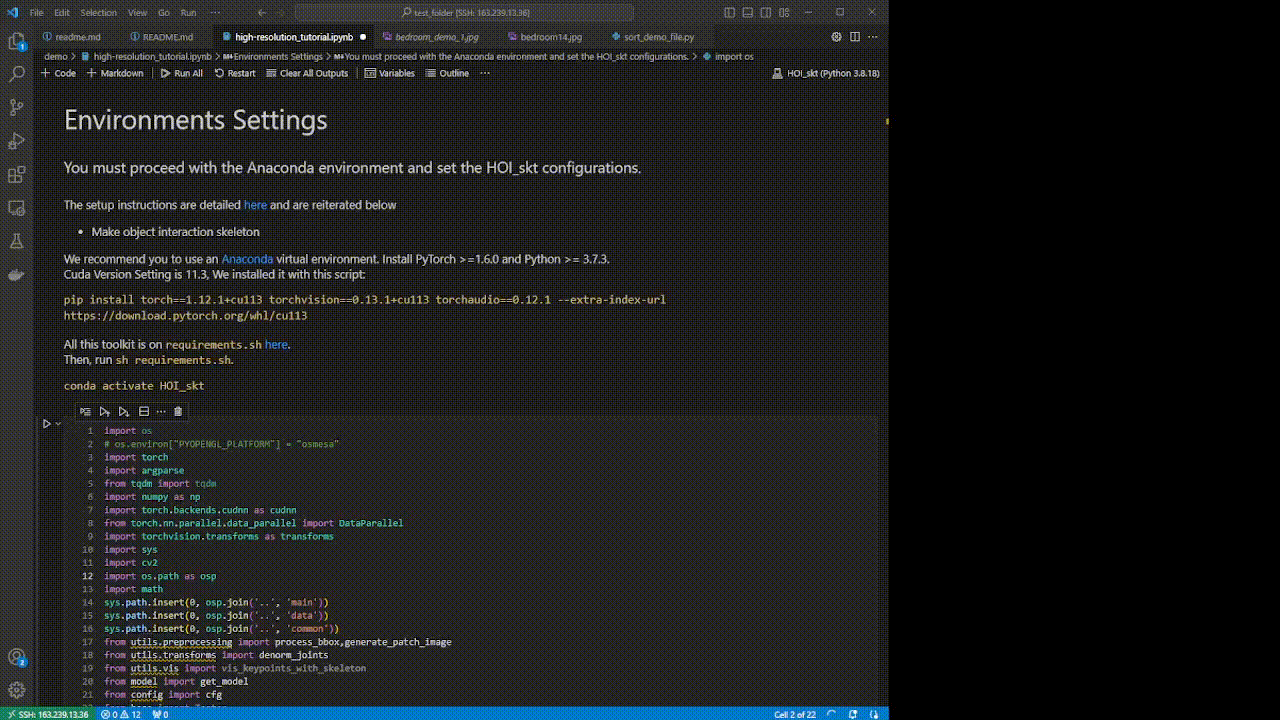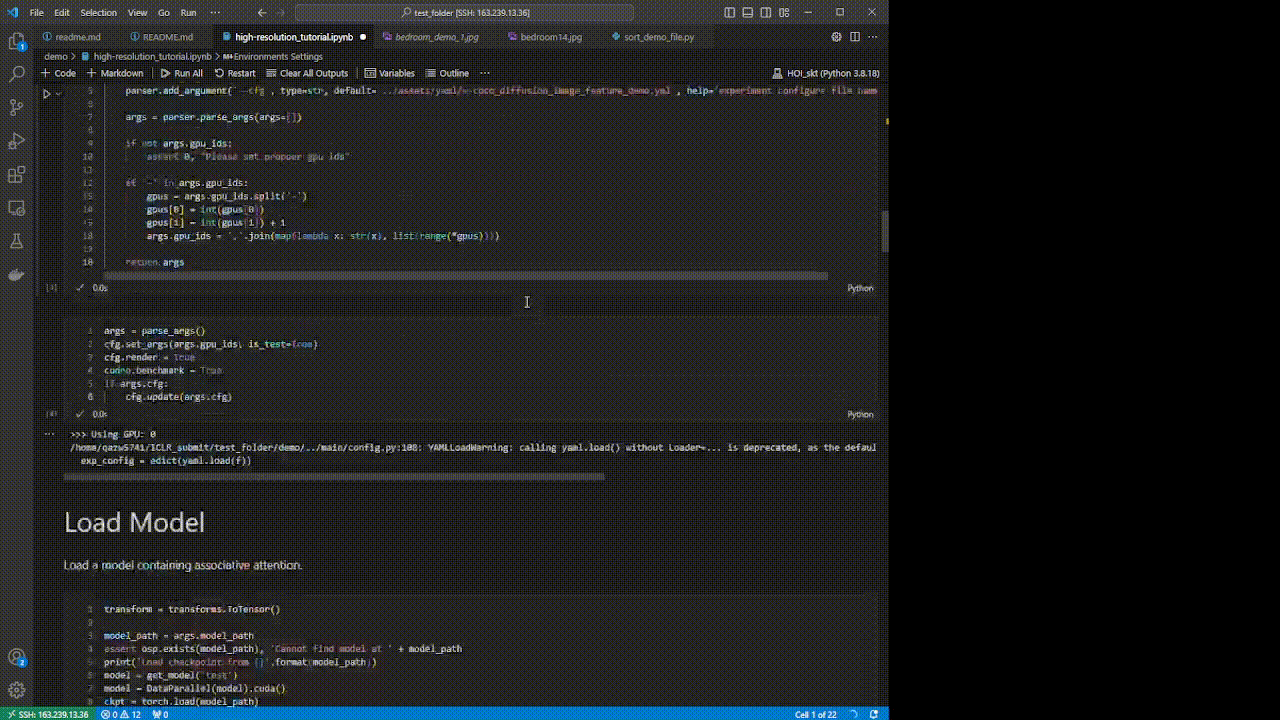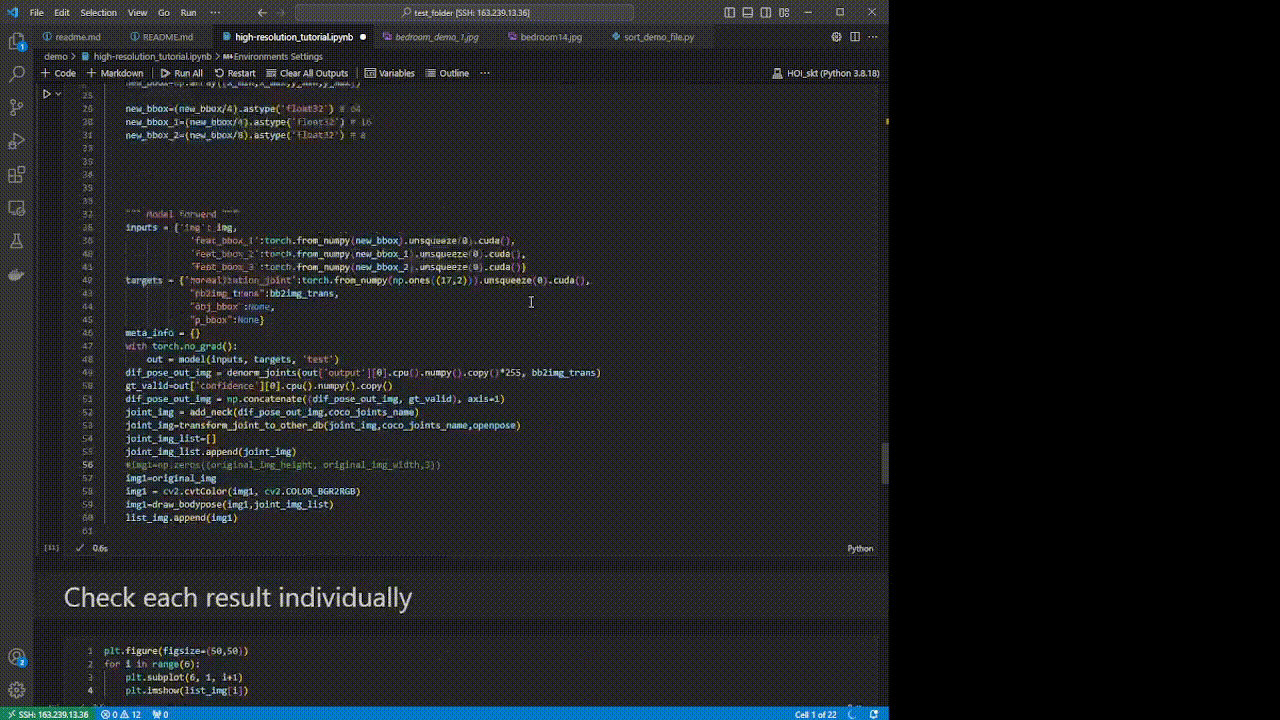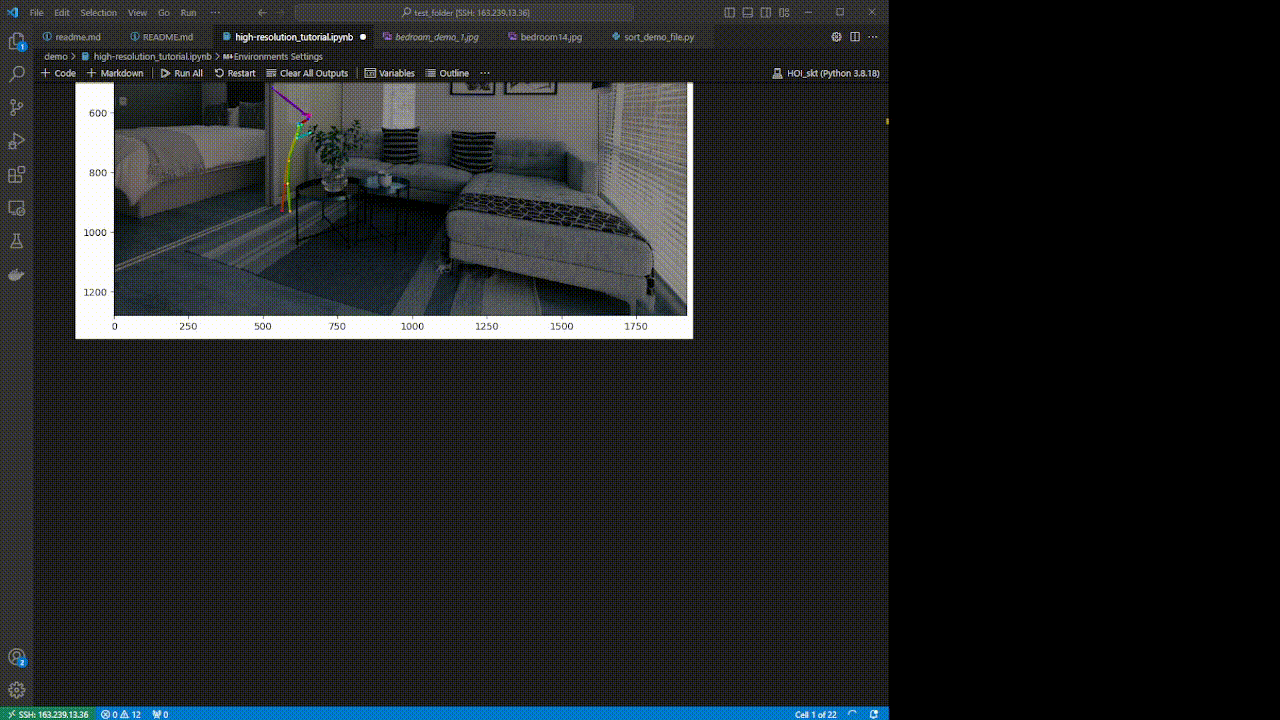
By employing our associative attention mechanism, the overall shape of skeleton becomes more natural as shown in images of a baby sitting on the bed or a man sitting on the yacht.
Moreover, our associative attention mechanism generates more object-interactive poses,
e.g. swinging, sitting, typing, as joints of the skeleton approach the object through propagation process.
Moreover, even in scenarios with multiple objects, a natural skeleton is generated while interacting with the specified object.


Comparion of CoModGAN, Instruct-Pix2Pix, SD-Inpainting and Ours:
We use a person bounding box, an object bounding box and a text prompt for HOI image editing.
In most cases of the visualization results, CoModGAN and Instruct-Pix2Pix perform poorly in generating natural humans.
Our results exhibit more object-interactive images than SD-Inpainting, as shown in cases of a woman with wearing a polka-dotted umbrella or a man surfing with the waves.
For an example, in the case of 'A woman in pajamas using her laptop on the stove top in the kitchen',
CoModGAN and SD-Inpainting did not generate even a human shape. Instruct-Pix2Pix failed to maintain the original image,
while our method generated a natural woman that matches the text prompt.


Performing on multi-people images:
This figure shows HOI-edited images of multiple people using SD-Inpainting, SDXL-Inpainting and Ours.
In the first and second column, SD-Inpainting and SDXL-Inpainting fail to generate a human when a person bounding box is provided in a small size.
On the other hand, our method generates natural HOI images regardless of a size of a person bounding box,
since it utilizes object-interactive skeletons. As shown in the fourth column,
people sitting on the sofa and children sitting on the sofa are generated naturally with our method.