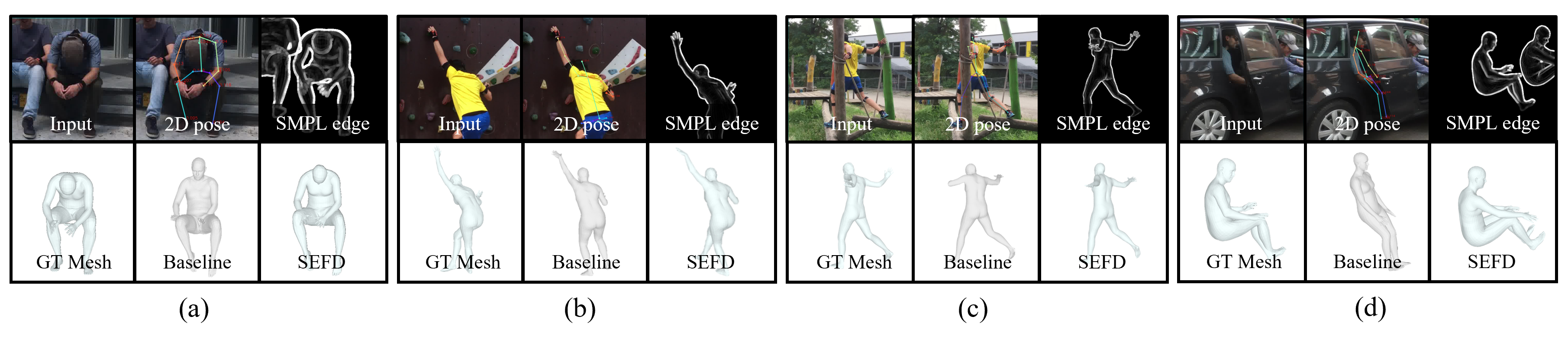
SMPL Edge Feature Distillation (SEFD)
The figure below is the overall flow of our method.
It consists of four components: Input Stage, SMPL Edge Generator, Teacher Model Training, and Student Model Training.
To train the Teacher Model, an SMPL edge map must be generated through the SMPL Edge Generator in the Input Stage. After this process, the generated SMPL edge map is concatenated with the Input image and used to train the Teacher Model.
After training the Teacher Model in this way, only the encoder of the Teacher Model is used to train the encoder of the Student Model through feature distillation. The input to the Student Model is obtained by passing it through a simple edge detector (e.g. Canny edge).
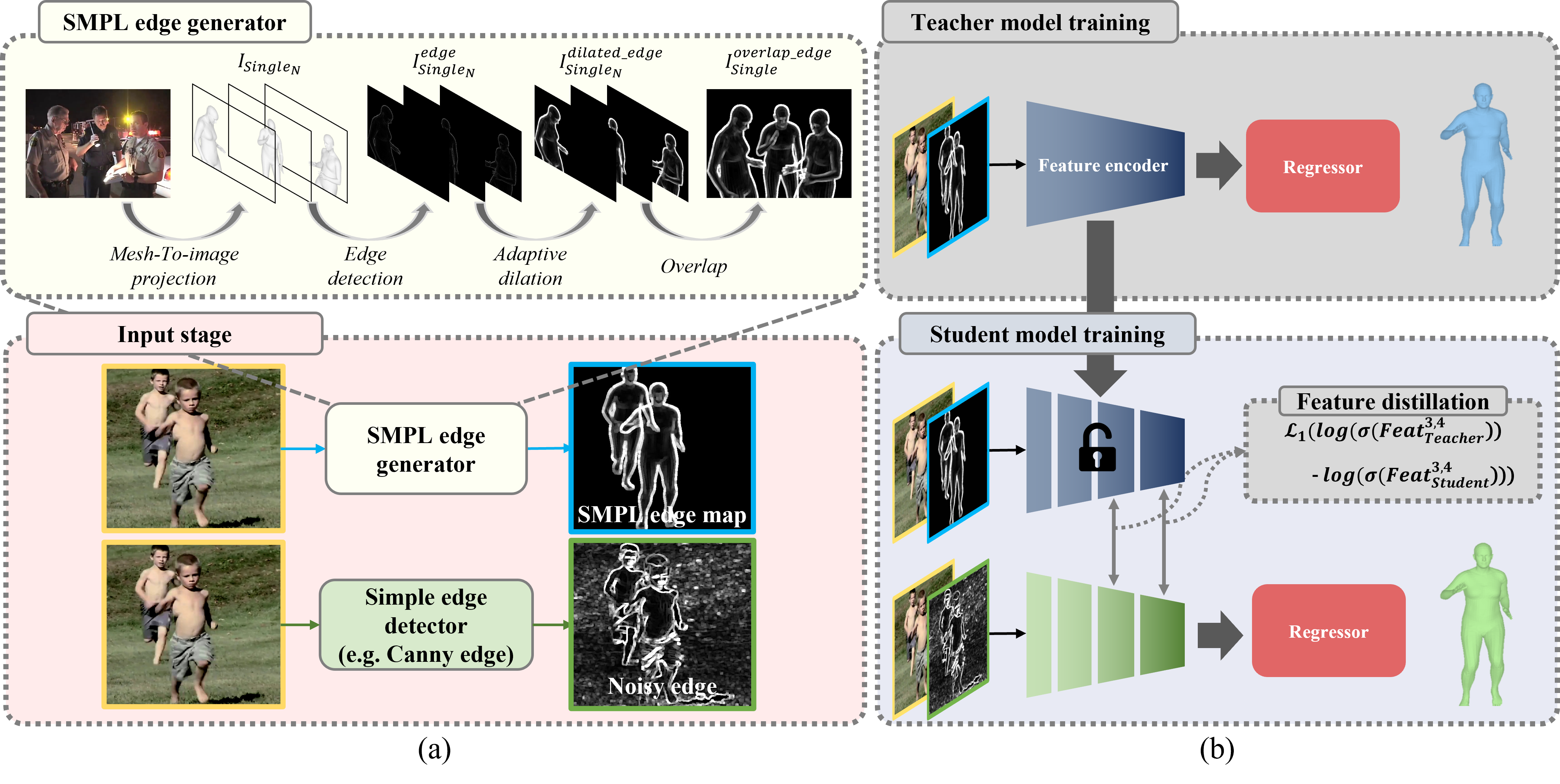
To elaborate further, the SMPL Edge Generator consists of Projection, Edge Detection, Adaptive Dilation, and Overlap. For the Loss in Feature Distillation,
we used the Log Softmax Loss that we found, and we connected the 3rd and 4th feature maps for Feature Connection.
An explanation of Adaptive Dilation is provided below
We have added a GIF animation below for your understanding. Please check it out if you need further clarification.

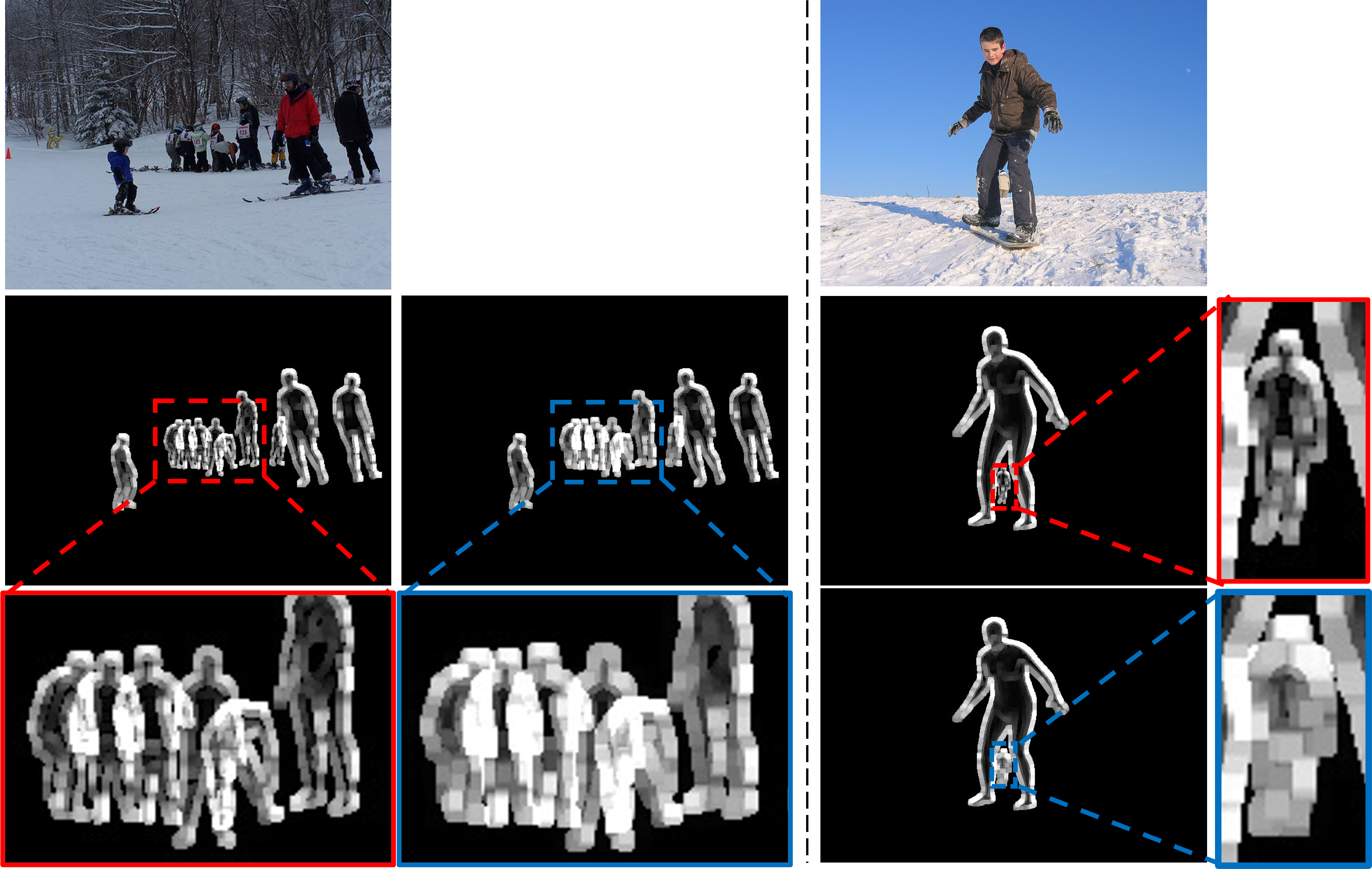
he above image shows an SMPL edge generator performing adaptive dilation.
The SMPL edge generator consists of four stages in total, including mesh to image projection, edge detection, adaptive dilation, and overlap.
The following image illustrates the motivation behind adaptive dilation
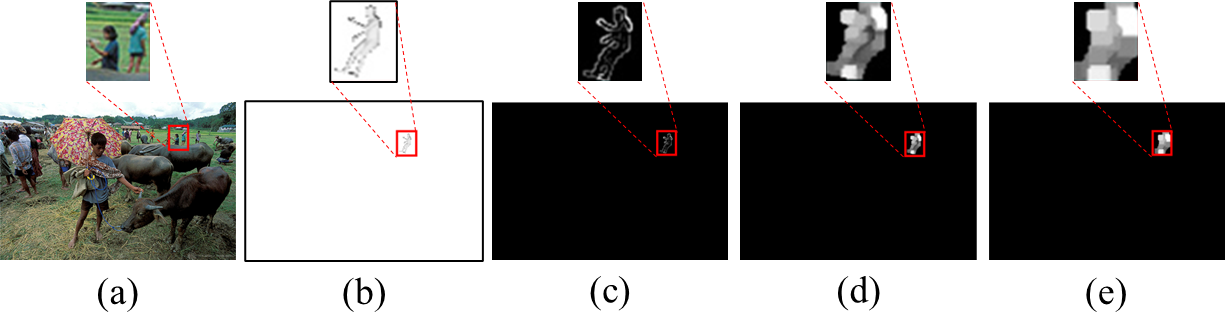
The image shows, from left to right, the input image, the mesh result for the pseudo ground truth in MSCOCO, the result of Canny Edge, the result of Canny Edge with dilation kernel 5, and the result of Canny Edge with dilation kernel 9.
Starting from the result (c), we can observe that without dilation at a very small scale, we can infer the human form and pose. However, from a kernel size of 5 or more, we can observe that the structural information of the human is distorted.
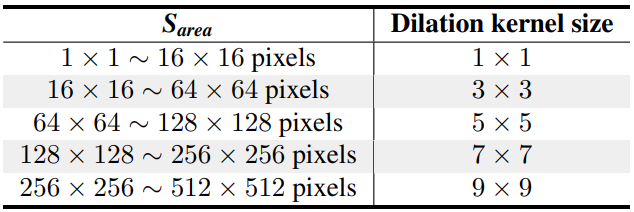
Therefore, we realized the need to adaptively adjust dilation from small to large scales, and solved this problem by adjusting the dilation kernel according to the area of the bounding box, as shown in the table above.
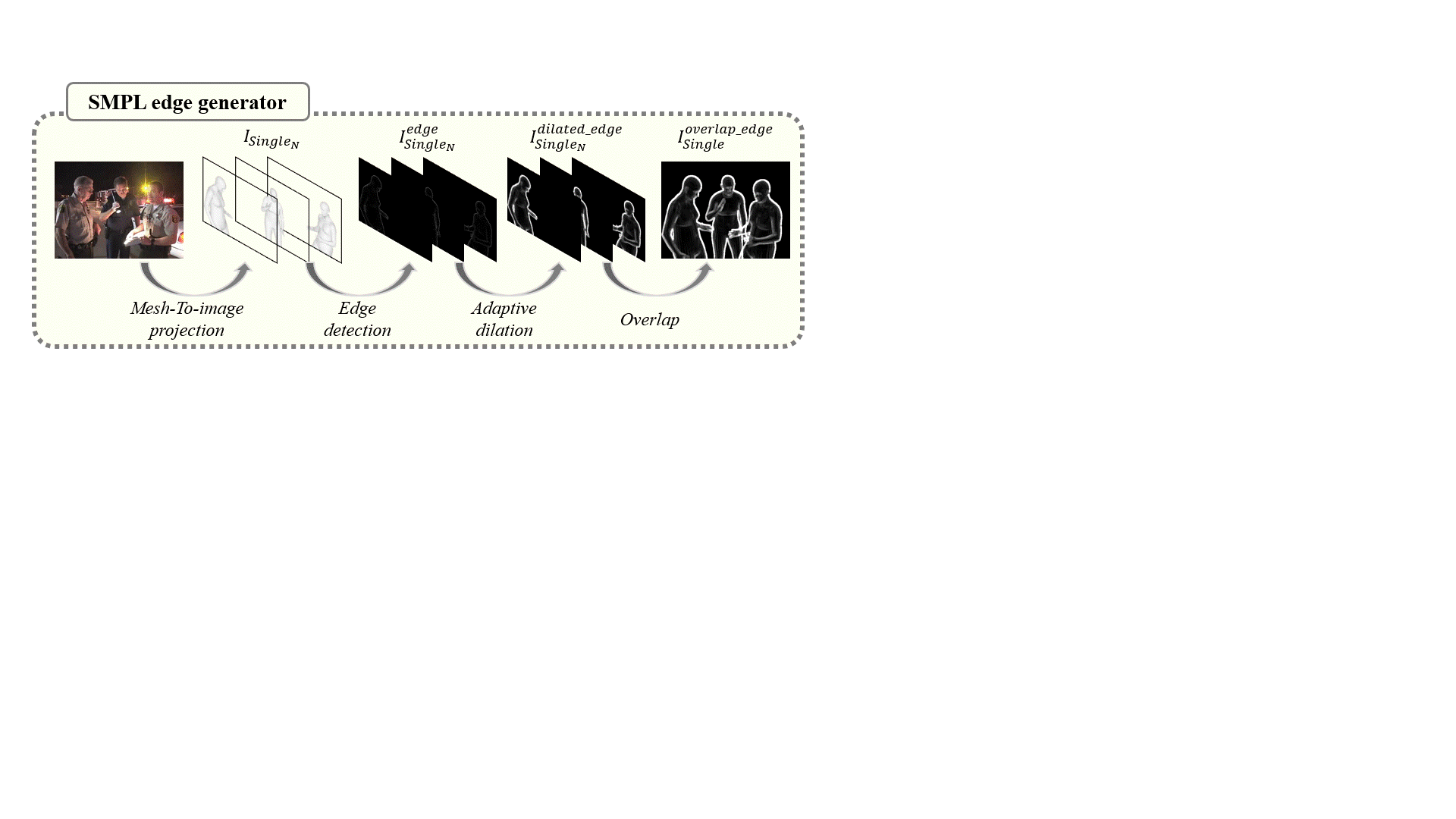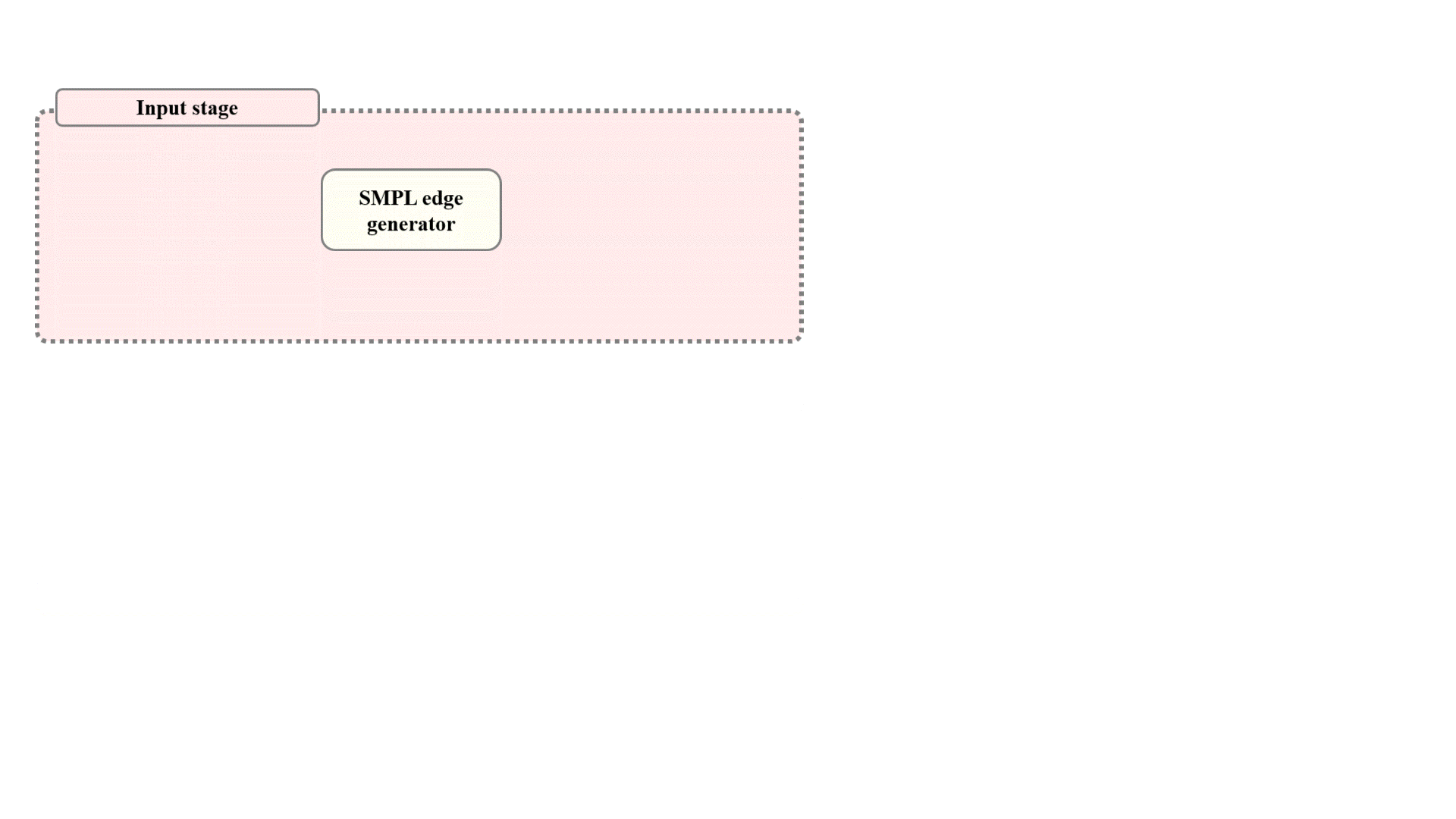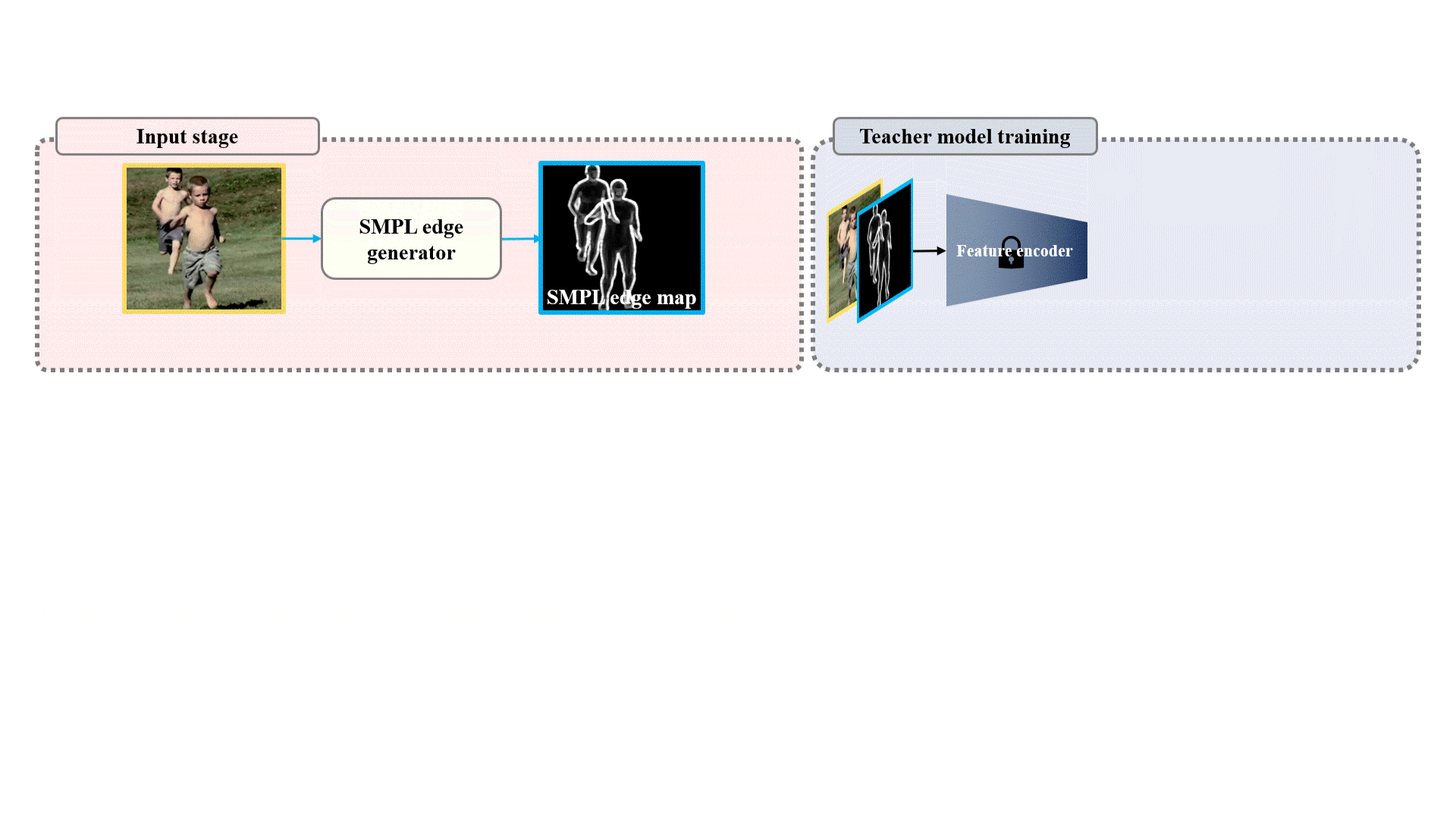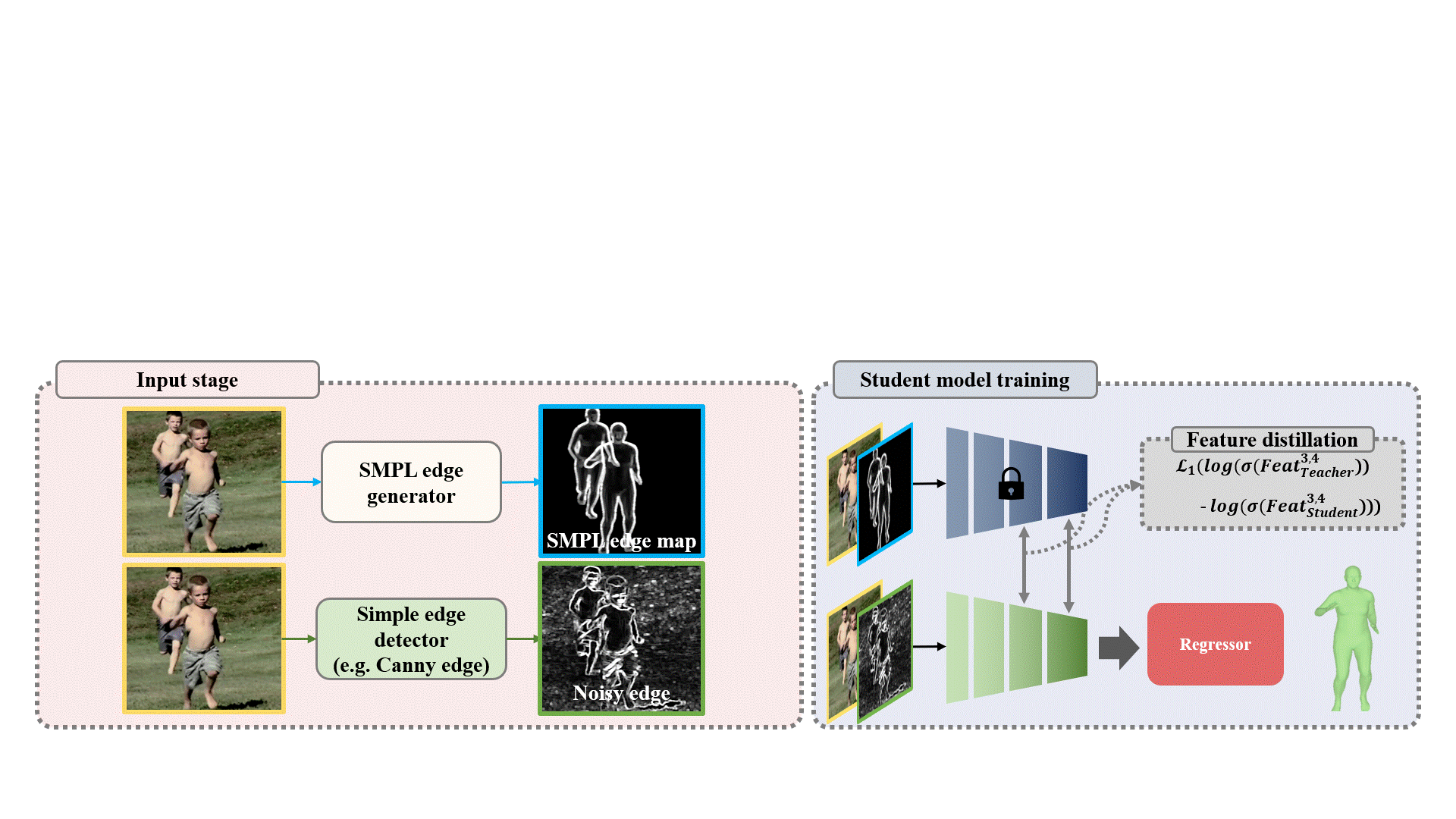
The above image was created to aid in understanding the training process through a video.
When training the teacher model, a GT SMPL edge map is created using the SMPL edge generator. Then, the input image is concatenated with the GT SMPL edge map, and the teacher model is trained appropriately.
Once the teacher model is adequately trained, only the teacher encoder is used to train the student model. Next, the input image is converted into a noisy edge using the simpl edge detector and concatenated with the student model for training.
During this process, only the 3rd and 4th feature maps from the encoder are distilled using logsoftmax loss.
Through this process, unnecessary boundaries in the noisy edges are removed, and only the necessary boundaries from the teacher model are used to train the student model.